🌿 Announcing distill_rag — A Simple Toolkit for Clean, | LiberIT
🌿 Announcing distill_rag — A Simple Toolkit for Clean, Truth-Aligned Data Pipelines
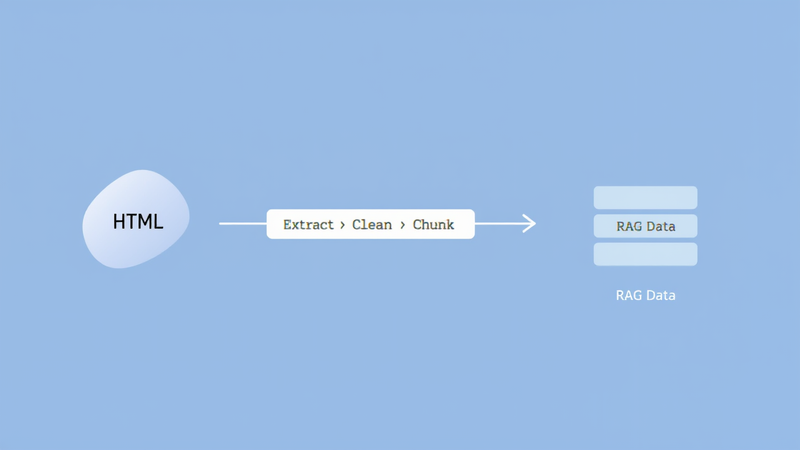
Over the past few months I’ve been working on a modular toolkit to help builders create cleaner, more reliable RAG pipelines. Today, I’m happy to share distill_rag, a small open-source project designed to make dataset extraction and long-chunk indexing easier for anyone working with transcripts, archives, or long-form spiritual or educational material.
This work is part of my ongoing effort at LiberIT to support tools that serve clarity, kindness, and open access. Many people building reflective or spiritually grounded models eventually find themselves stuck at the same point: noisy HTML, scattered transcripts, inconsistent formatting, and no clear path from raw text to high-quality searchable chunks. The early stages of a distillation pipeline shouldn’t be a mystery, and they shouldn’t require reinventing the wheel each time.
distill_rag keeps things simple. It focuses on the foundations:
🧹 Clean Extraction
It removes scripts, ads, navigation bars, and boilerplate, leaving only the meaningful text.
📄 Structured Sessions
Raw HTML becomes {title, turns[]} JSON sessions. Each page is turned into clear user/assistant “turns,” useful for question-answer datasets or RAG-assisted training.
📦 Long-Form Chunking
Instead of tiny slices of text, the toolkit creates cohesive 5–9k-character segments. These preserve context and flow — especially important for spiritual writings or long teachings.
🧠 Local Embeddings
It works seamlessly with local embedding models (including Ollama), keeping your pipeline private and under your control.
🔍 Elasticsearch Vector Index
A full Elasticsearch v8 vector index is created automatically, enabling fast semantic search across your entire corpus.
🧪 Tested and Modular
Everything is covered by a test suite, and each part can be used independently or as part of a larger system.
Why I Built It
My own work often involves long, reflective material — teachings, transcripts, and spiritual discussions that deserve to be handled with care. Many of the newest AI models benefit from high-quality distillation pipelines, but the starting point is always the same: a clean, reliable dataset.
I wanted a tool that:
- removes noise without damaging meaning
- preserves the natural structure of conversations
- creates long, coherent chunks that actually mirror human thought
- is easy for others to adopt, adapt, or extend
- supports people building truth-aligned, service-oriented systems
If distill_rag helps even a few people create cleaner or kinder models, then it’s done its job.
Get the Project
GitHub: https://github.com/elspru/distill_rag
Hugging Face Space: https://huggingface.co/spaces/htaf/distill-rag
You’re welcome to explore it, fork it, or contribute improvements. I’d be glad to hear how you use it — whether for research, teaching, spiritual work, or building your own RAG pipeline.
Closing Thoughts
Technology can support growth when it’s rooted in clarity and service. My hope is that distill_rag helps others work with their text collections more gently and effectively, creating stronger foundations for whatever models or tools they’re building.
If you’d like help setting up your own pipeline or want to collaborate on related work, feel free to reach out.
Blessings and onward.